近几年实时需求涌现,尤其是银行更加重视挖掘实时数据的使用与价值,主要表现在逐年增多的实时报表、实时大屏等面向 BI 的场景;还有实时指标或特征计算等面向 AI 的场景。
从技术角度,实时 OLAP 相较于传统 OLAP 发展起步较晚,多种多样的实时数据需求,对实时 OLAP 体系也提出了更高的要求。随着近年来技术迭代,如 StarRocks、ClickHouse 等支持实时 OLAP 场景的数据库也是推陈出新,对于解决银行业的实时场景带来了更多可能。 中原银行2018 年首次引入实时计算业务,主要以代码开发为主。2019 年开始系统的建设实时计算平台,以 Flink SQL 开发实时业务,能够界面配置、启停、监控任务。2020 年支持运行在 K8s 云平台上,能够手机小程序远程监控,承载的任务也达到了 100 多个。2021 年开始支持 CDC 同步场景,探索实时 OLAP,承载的业务也达到了 200 多 个。2022 年支持了最新的 Flink Table Store(Apache Paimon) 湖存储,也引入了高性能的 OLAP 引擎 StarRocks,探索实时报表场景,承载的业务也达到了 300 多个。
实时OLAP场景:当你存入一笔钱,银行的系统会有什么变化?
以银行的典型动账场景为例,一次动账操作其实是一个事务,至少要操作两张表。第一张表是交易流水表,记录转账的一次行为;第二张则是用户的属性表,其中有一个字段是用户的余额,需要随着转账同步更新。

上图中的两个表是演示两次转账动作,该场景在 12:00:01 秒张三转入 100 元,客户表张三的余额也从 100 更新为 200。12:00:02 秒,李四转出来 100 元,客户表李四的余额也从 200 元更新为 100 元,在这个转账场景下进行分析。
流水表的特点,主要是 insert 操作,记录行为信息,适合增量计算,如统计开户、取款、贷款、购买理财等行为事件。基于 Kafka 的实时计算能够较好的解决该场景,比如实时营销包括大额动账提醒、工资代发、理财产品购买、申请反欺诈、交易反欺诈等。在贷后管理也有应用,如零贷贷后临期催收、扣款等。 客户属性表的特点,主要是 update 操作,记录属性信息,客户的总资产、贷款、理财、基金、保险等产品的余额是在维度表中,所以常使用维度表全量计算资产信息,如资产余额类的计算等。应用的场景主要是实时报表和实时大屏,比如对公 CRM、零售 CRM;经营管理;资产负债管理等。 在中原银行,基于事实表的场景基本上已经解决。但银行业的报表大多都基于维度表的统计分析,该场景也是银行业实时报表落地困难的关键因素之一。接下来主要探讨,基于维度表的实时全量计算场景。 以对公 CRM 实时存贷款场景为例:该业务面向总分行领导、支行行长、客户经理等,随时查看行内分支行及客户的存贷款情况,从而时刻掌握全行的资产最新状况。

实时场景仅有实时数据往往是不够的,需要配合离线数据才能计算出所需的业务数据。尤其是在银行体系下,面向规范化、精准化加工的传统离线数仓体系,能够较好的解决财务分析等场景,从该场景的数据角度来看,分为三个部分,实时数据、离线数据、实时查询分析数据,也就是在查询的时候才开始进行逻辑计算。
先来看一下实时数据,不断变化的有存款余额、贷款余额、应解汇款、实时汇率、新开账户等。离线数据主要包括员工信息、机构层级、归属关系等基本信息,还有离线跑批生成的年末月末余额、绩效关系、管户关系等。 这两部分数据均载入到实时 OLAP 引擎 StarRocks ,用户查询的时候在引擎内计算资产负债明细汇总,根据绩效关系对资产负债进行分组聚合。实时的存贷款和日终、月终进行比较,分支行根据存贷款进行排序等。对公 CRM 提供的查询功能有全行汇总、分支行汇总、分支行明细、分支行下转、客户明细、年末月末比较、趋势分析等。 了解了实时存贷款业务功能,再进一步详细拆解数据流程: 该案例的技术架构图,使用了实时的 ELT。
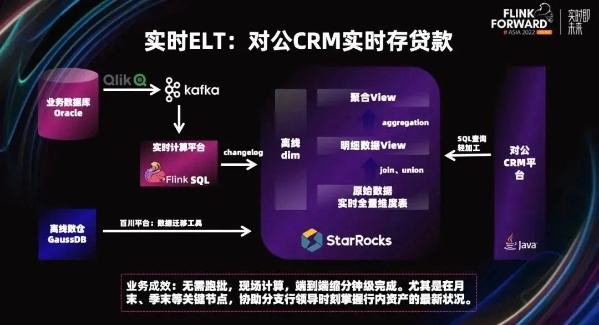
首先,实时数据全部来自于 Oracle 数据库,通过实时采集导入到 Kafka。使用流计算平台,以 CDC 的形式写入到 StarRocks,在其中构建全量和增量的数据。作为 ODS 原始层,离线数据在数仓中跑批生成,使用离线同步工具,百川平台以 T+1 的形式写入 StarRocks,然后在 StarRocks 中使用 view 灵活的对数据进行转换处理。View 视图可以随业务进行调整,上层应用直接查询封装好的视图实现即席查询。当用户进行点击的时候,触发原始的数据进行计算,如查询某分行的存款余额。 该方案可以解决基于维表的实时全量计算场景,无需跑批,现场计算,端到端分钟级甚至秒级完成。尤其是在月末、季末等关键节点,给分支行的领导查询最新资产负债等信息带来了极大的便利。 当然,该方案并不完美,缺点是当 view 的逻辑较为复杂,数据量较多时,查询性能影响较大,因此比较适合数据量不大、对 QPS 要求不高、灵活性要求较高的场景,且需要计算资源比较充足。 该方案的探索也得出了一个宝贵的经验。虽然 OLAP 引擎性能强大,但仍然不能把所有的计算逻辑全部在引擎中执行,必须向前推移。但是 Flink 只有计算没有存储,这个问题该怎么解决呢? 今年发布的 Flink Table Store (Apache Paimon) 能够很好的解决之前遇到的问题。Flink Table Store (Apache Paimon) 是一个统一的存储,用于在 Flink 中构建流式处理和批处理的动态表,支持高速数据摄取和快速查询,是一种湖存储格式,存储和计算分离。还支持丰富的 OLAP 引擎生态,比如 Hive 等。我还了解到 StarRocks 也支持数据湖查询,相信在不久的将来 StarRocks 也能够支持查询 Flink Table Store(Apache Paimon) 。

