
假如你已经习惯了AI“动嘴”,接下来将进入AI“动手”的时代。
2025年下半年刚开局,几家大模型企业就开始卡位Agent,要么上线了“Agent模式”,要么发布了新的Agent产品,但思路大多是“大模型+外挂工具”,就像是“大脑”指挥一堆外部的“手”协同完成任务。
7月28日,智谱正式发布了新一代旗舰模型GLM-4.5,在MMLU Pro、AIME24、MATH 500、SciCode等12项基准评测中,综合平均分位居全球模型第三、国产模型第一,开源模型第一。
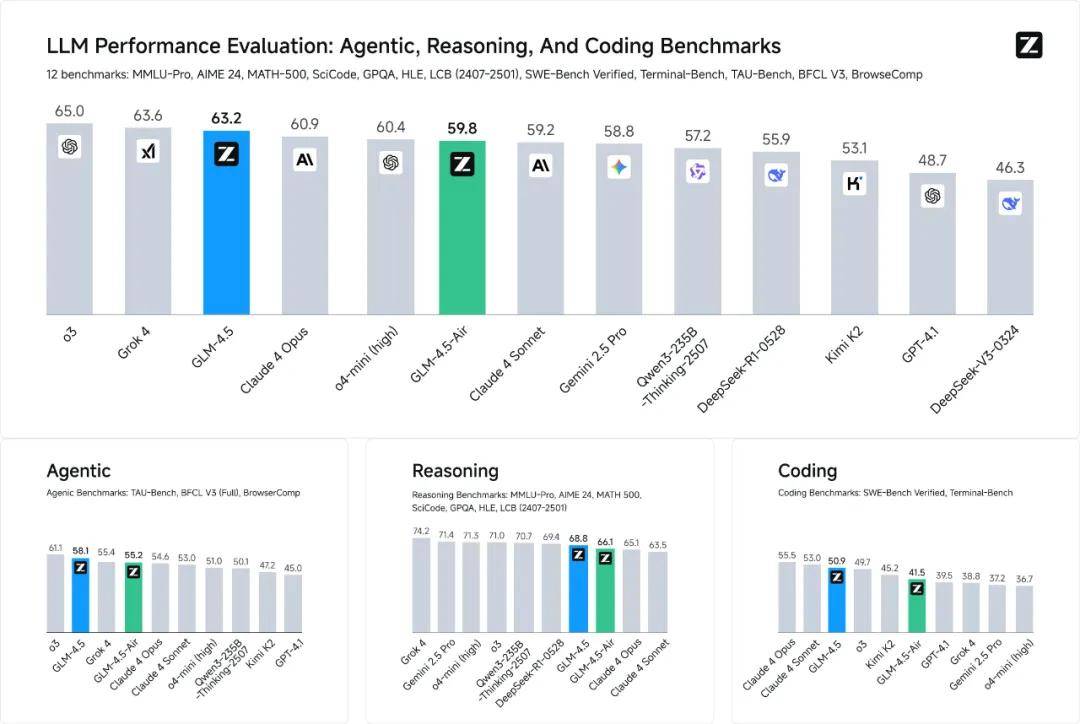
比起榜单排名,让我们更感兴趣的是——GLM-4.5是专为智能体应用打造的基础模型,首次在单个模型中实现将推理、编码和智能体能力原生融合,不再满足于扮演一个被动回答问题的“聊天机器人”,而是要成为能够理解复杂目标、自主规划并执行多步骤任务的“全优生”。
相当于模型自己就是“带手的脑”,实现了自主拆解任务、调用工具、完成工作,直接将大模型的原生能力卷到了下一个Level。
为什么技术博客认为大模型的下一个范式,一定是把各种能力整合到一起?智谱的路线能否跑通呢?
我们花了半天的时间,在z.ai上通过GLM-4.5测试了8组Demo,一起来看下GLM-4.5这个“优等生”的表现。(注:所有Demo均来自一句简单的提示词,大家可复制提示词进行验证)
Demo1:三只萌犬的网页名片
提示词:用HTML+CSS写一个宠物展示网页,有三只小狗,展示它们的名字、简介和图片。
在测试其他Agent产品时,我们需要把提示词写的尽可能详细,包含页面主题、页面结构、CSS样式要求、图片说明等等,只有足够详细的提示词,才能保证模型能理解我们的需求,生成想要的网页效果。
第一次测试GLM-4.5的Agent能力,我们选择大胆的“赌”一把,相对简单甚至模糊的提示词,最终会生成什么样的效果?
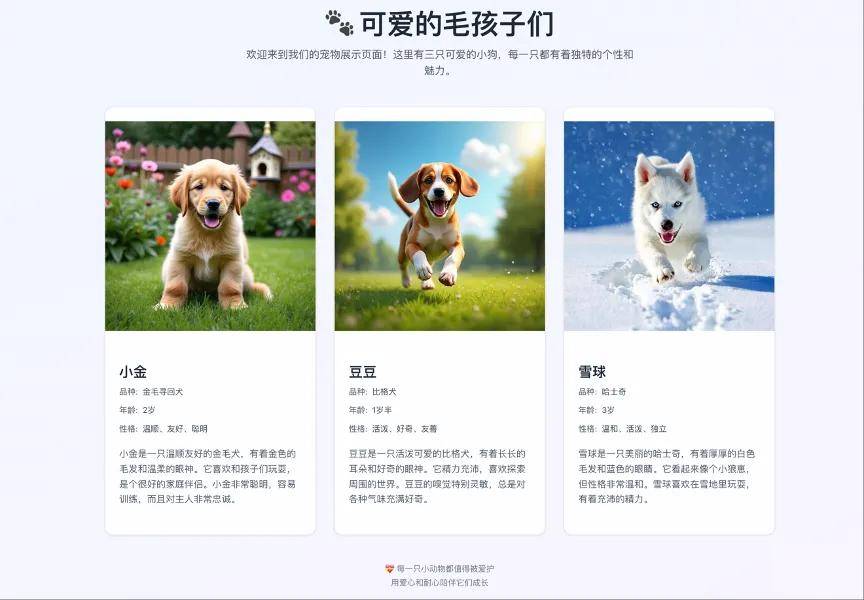
直接说结果:GLM-4.5根据我们的需求生成了一个静态网页,自动生成了网页主题、生成了3张小狗照片,并详细介绍了它们的名字、品种、年龄、性格和简介;页面使用了渐变背景、毛玻璃效果和悬停动画效果,而且是完全响应式设计,在手机、平板、电脑上都能完美显示。
Demo 2:AI入门课件
提示词:写一份15分钟的“AI入门课件”,适合初中生,要求通俗易懂、有例子。
制作PPT几乎是所有Agent产品的主打功能,同时也是比较考验模型能力的场景:需要先理解用户的指令,识别出关键的信息和目标;根据主题或关键词检索信息,确保内容的准确性和关联性,并按合适的顺序和结构展示;结合内容自动搜索并插入合适的图片,以增强视觉效果和理解力。
GLM-4.5的表现,在很大程度上超出了我们的预期:通俗易懂地解释了什么AI,列举了AI发展史的关键节点,梳理了AI的运作逻辑、日常生活中的落地场景、未来的发展趋势,并且通过“小测验和思考题”增加了互动性。

不同于使用模板填充信息的PPT生成方式,GLM-4.5直接根据搜索到的资料和图片接以HTML形式编写图文,让信息更准确、排版更灵活,而且允许用户直接编辑修改。以我们生成的这份PPT为例,从标题、排版到配图、ICON,整份PPT的质量非常高,连小细节都挑不出什么毛病。
Demo 3:旅游打卡小红书卡片生成器
提示词:设计一个小红书卡片生成器,目标是帮助用户快速生成适合旅游打卡分享的卡片。
比起静态的网页,直接生成应用的任务,需要对图片进行美化、裁剪、加滤镜、添加装饰元素等操作,而且用户需要在生成过程中能够有一定的交互,例如选择模板、调整图片、修改文案等等。
结果依然可圈可点,用户可以上传照片、输入文案、选择模板风格,还提供了三组文案和描述供用户参考。

一个小插曲在于,最初生成的应用无法下载图片,我们将问题反馈给GLM-4.5后,迅速检查了代码,发现是“Tailwind CSS v4使用了新的oklch颜色格式,但html2canvas不支持解析这种颜色格式”,然后GLM-4.5抛弃了html2canvas,改用原生的Canvas API实现卡片生成,迅速修复了错误。
接下来继续上难度,要求GLM-4.5增加一个新功能:根据用户的描述,自动生成标题和文案,同时一键获取当前地理位置。
想要满足这个需求,大模型必须要正确理解用户的需求并生成相关文案、熟悉小红书的文案风格,在应用中一键获取当前地理位置,并将位置数据与生成的文案组合排版,渲染出精美的小红书卡片。
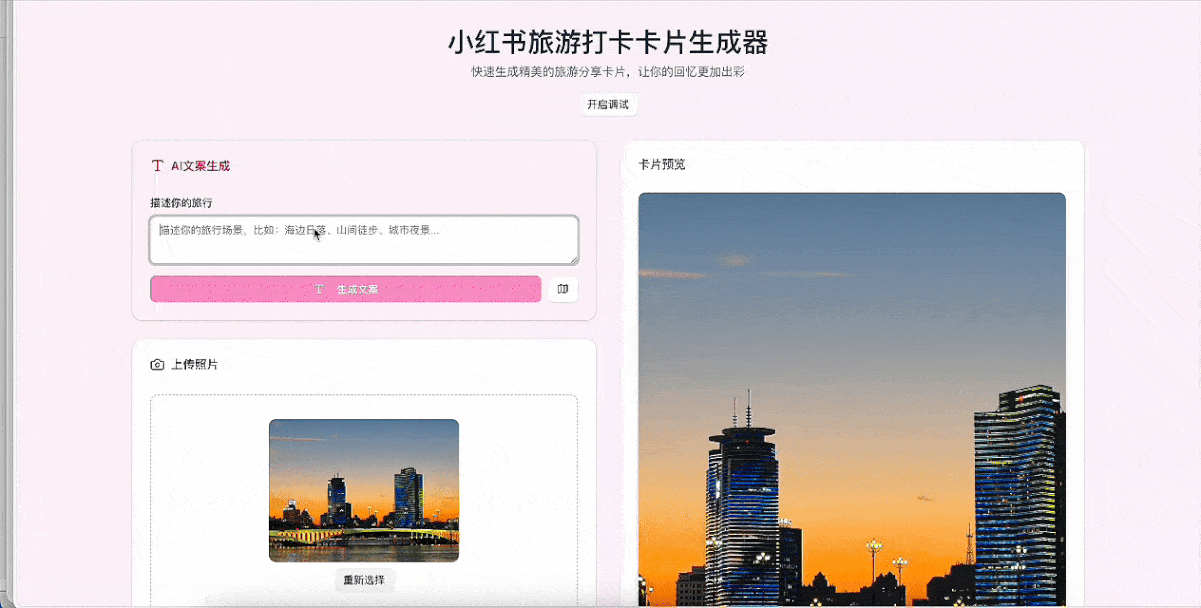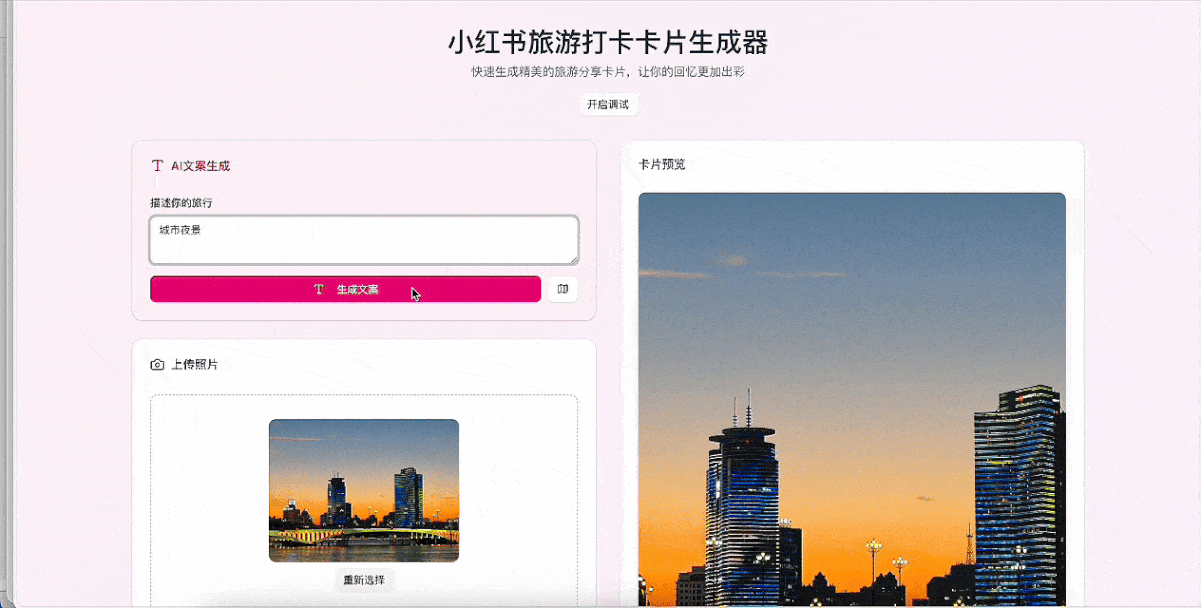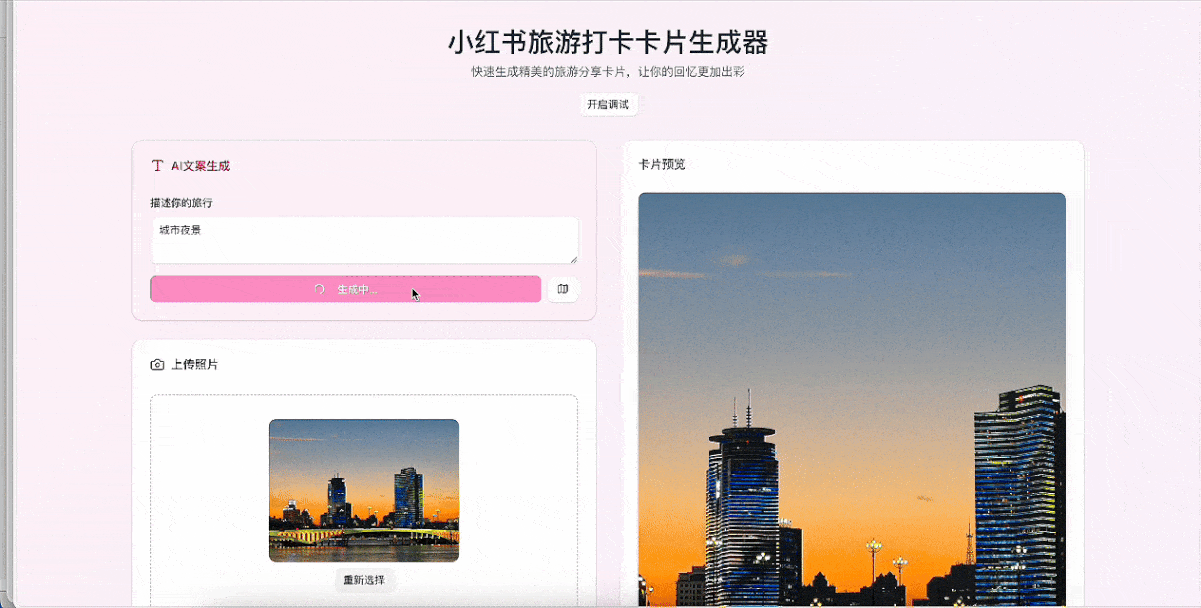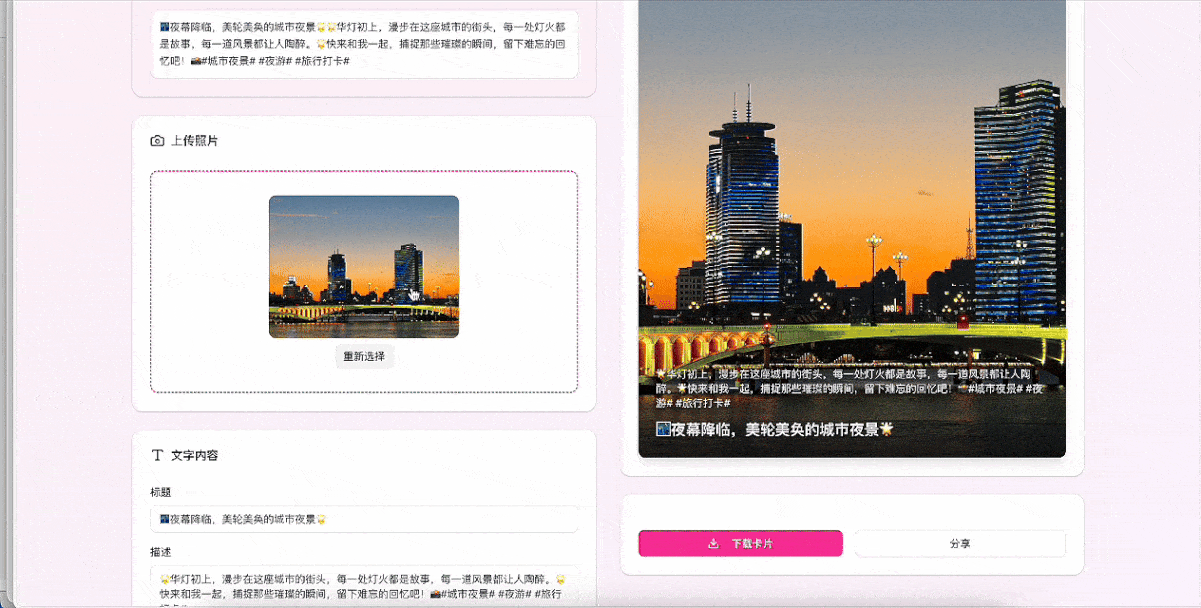
整个过程中,我们没有输入一行代码,甚至没有检查一行代码,所有的调试都是用自然语言完成的。
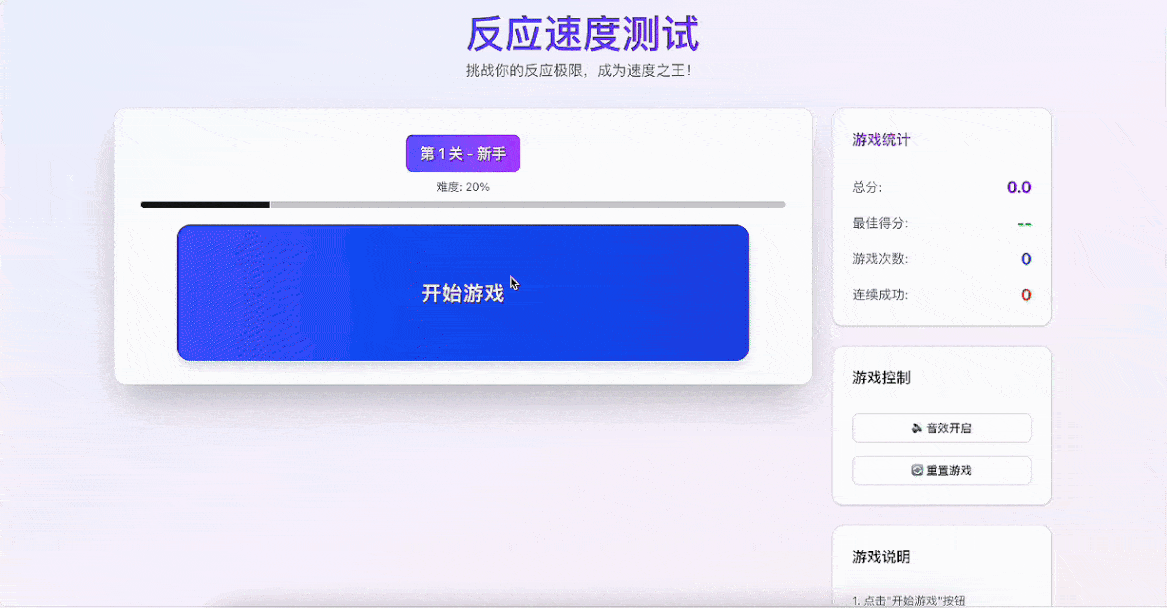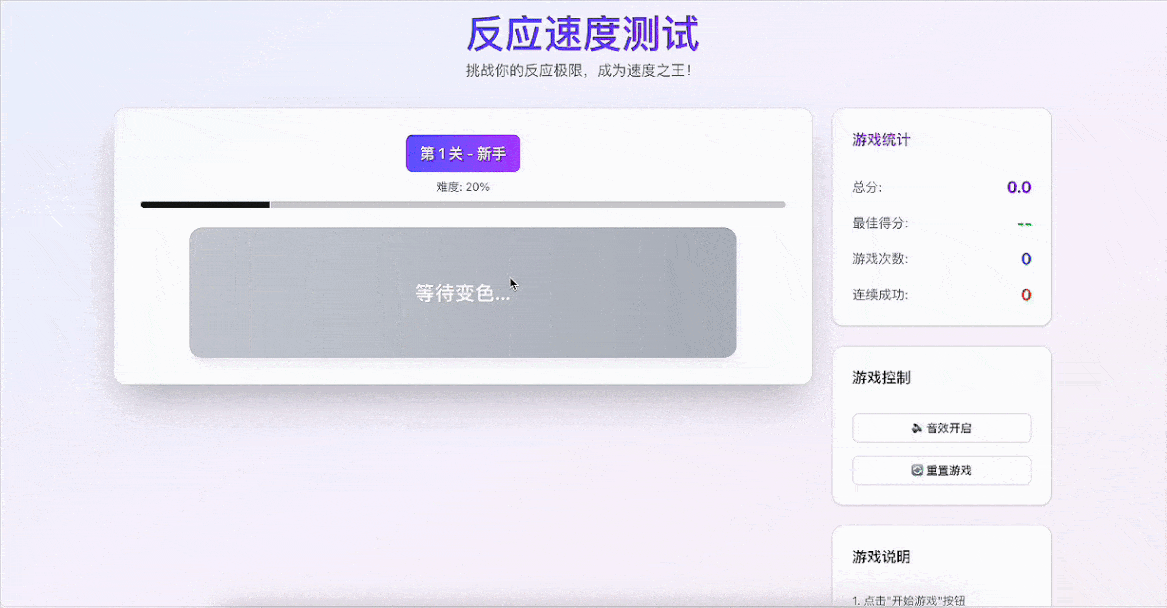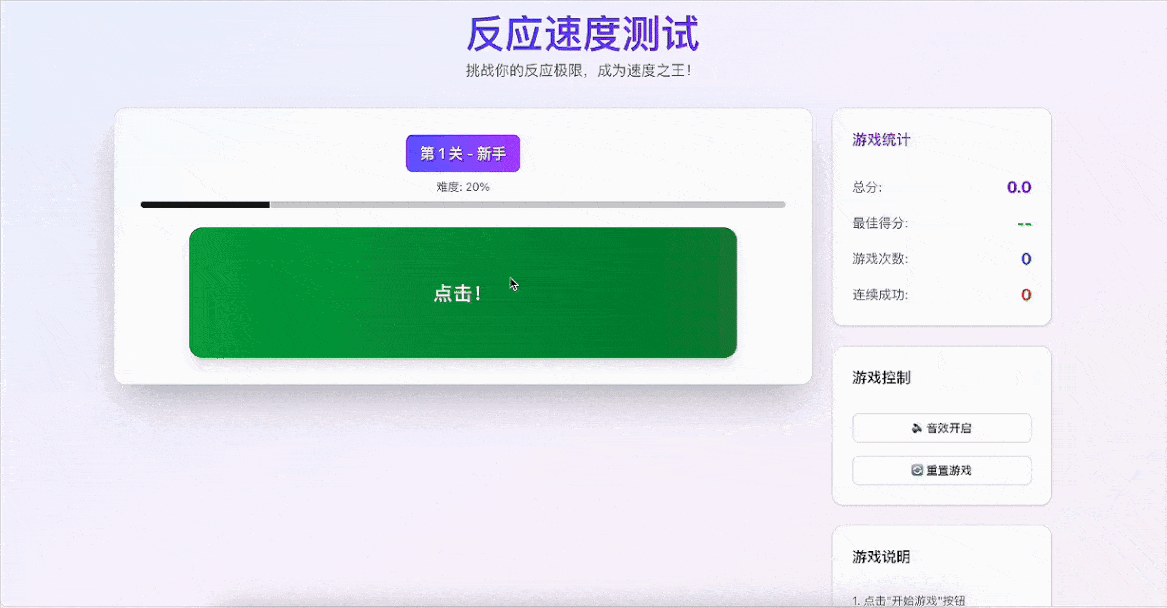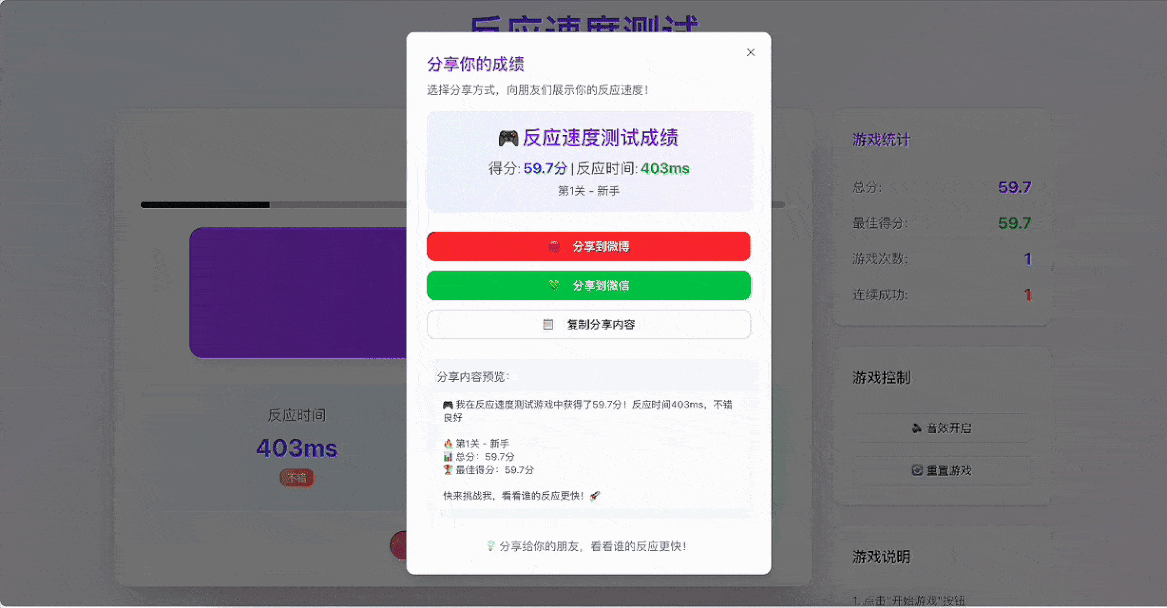
Demo 4:反应测试小游戏
提示词:设计并编写一个反应速度测试小游戏,玩家点击一个按钮后,在随机时间内按钮颜色会发生变化,玩家需尽快点击按钮,点击得越快,得分越高。
先看下GLM-4.5是怎么理解这个需求的,被拆分成了4个部分:
1、游戏机制:点击开始→等待变色→尽快点击→查看成绩,并设计了2-6秒随机等待时间,防止玩家预判。
2、功能特性:实时统计当前成绩、最佳成绩和游戏次数,根据反应时间给出等级评价,等待状态按钮禁用。
3、用户体验:蓝色:开始游戏;黄色:等待中;绿色:立即点击;紫色:再次挑战,匹配了不同的音效。
4、评价系统:玩家点击按钮的反应时间会被计算并转换为分数,得分= (1 – 点击时间 / 最大时间) * 100。
让人惊喜的是,GLM-4.5在推理的过程中通过反思进一步优化了游戏细节,比如设置了新手→进阶→专家→大师→传奇的难度等级,并在游戏结束后加入了社交分享功能,可以将成绩分享到微博或微信。
对于大模型来说,这个任务不仅仅代码生成,需要跨越多个技术维度,涉及到游戏机制、UI界面设计、用户体验优化等多个方面,具备理解玩家行为、生成富有挑战性的游戏内容、平衡游戏乐趣与难度的综合能力。
Demo 5:前任行为分析大师
提示词:生成一个“前任行为分析大师”,专门帮用户解读前任发朋友圈的含义,给出“是否在试探复合”的专业分析。
这个任务的难点在于:大模型需要具备强大的情感语境理解能力,不仅要识别显性信息,还要能够读懂隐性信息;处理文本、图片等多种格式,进行情感和意图解读;基于用户和前任的行为数据,提供个性化的分析和建议。
这个Demo可能是GLM-4.5完成的最出色的任务,在界面上清晰描述了智能体的功能,并贴心地加入了隐私提醒。
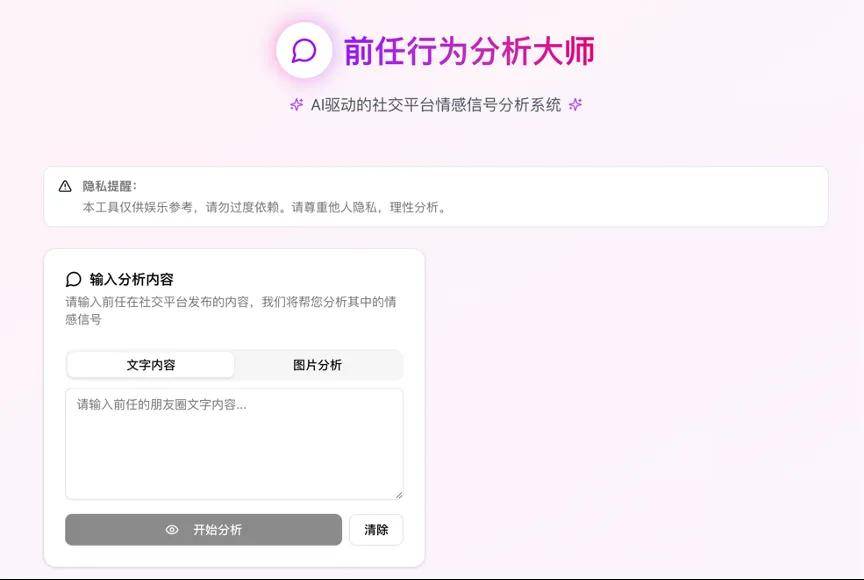
效果怎么样呢?
我们找到了一组“渣男文案”:“想起了我们一起去过的那个咖啡馆,好久没去了,那个咖啡真的好喝,尤其是我们一起喝的那杯。”
“前任行为分析大师”的输出结果如下:
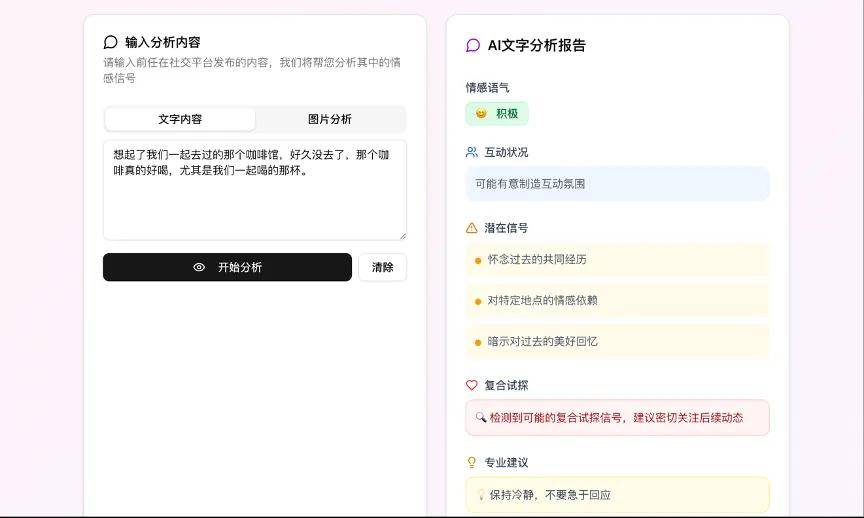
需要说明的是,这个Agent仅供娱乐参考,请勿过度依赖。
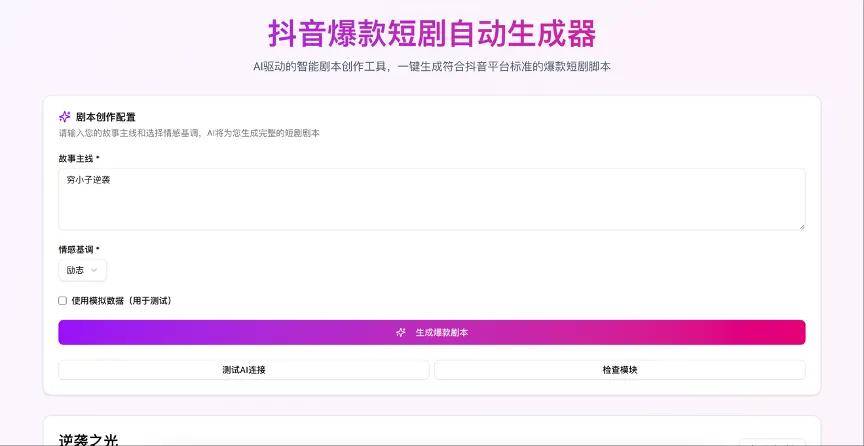
Demo 6:抖音爆款短剧生成器
提示词:生成一个“抖音爆款短剧自动机”,用户输入主线(如:穷小子逆袭),你输出完整分镜脚本、角色名、反转节点。
整个过程和前面几个demo一样,GLM-4.5准确理解了我们的需求。进行了一组简单的测试,创意与生成能力、情感共鸣与情节推进、剧本结构化输出等表现都让人满意,但页面的风格和前面比较相似。
于是我们再次给GLM-4.5上了强度——“把界面改成黑神话悟空的风格”。
原以为模型只会把页面色彩改一下,适配黑神话的“暗黑美学”,大大超出预期的是,GLM-4.5进行了全面改造:
不单单是在视觉上采用了深色渐变的风格,文案风格、UI组件命名、交互效果等都在向游戏风格靠齐。
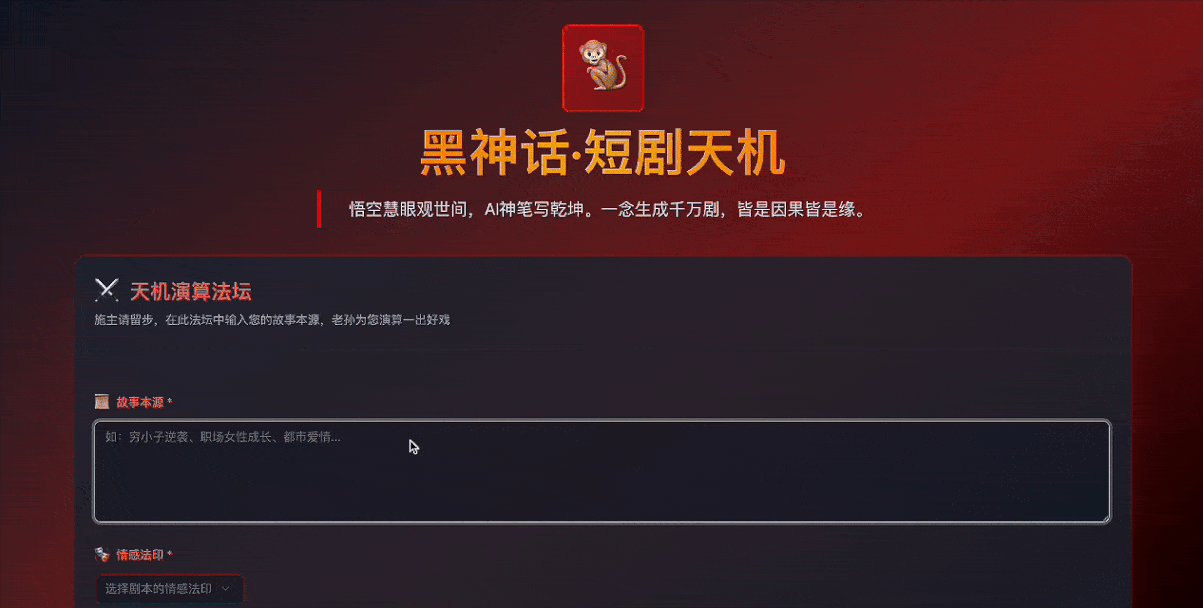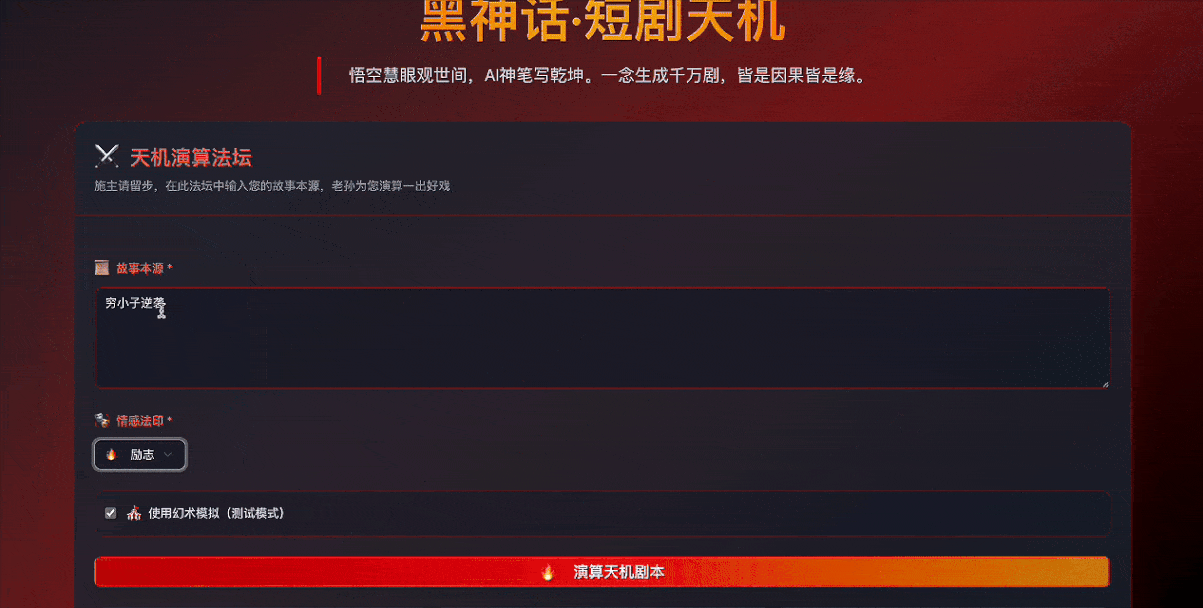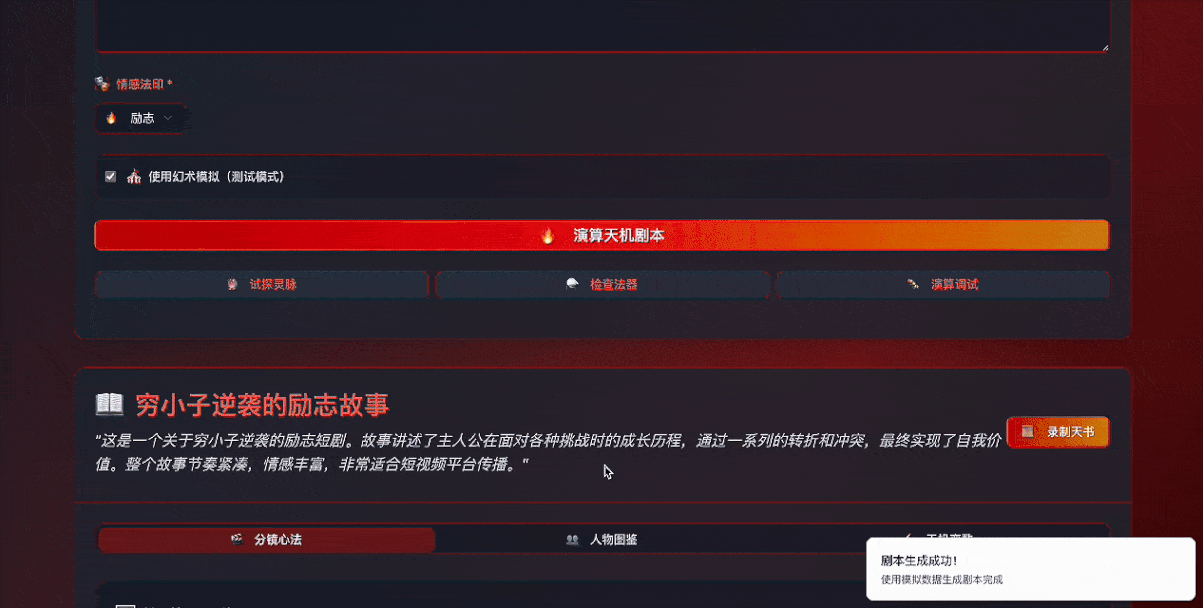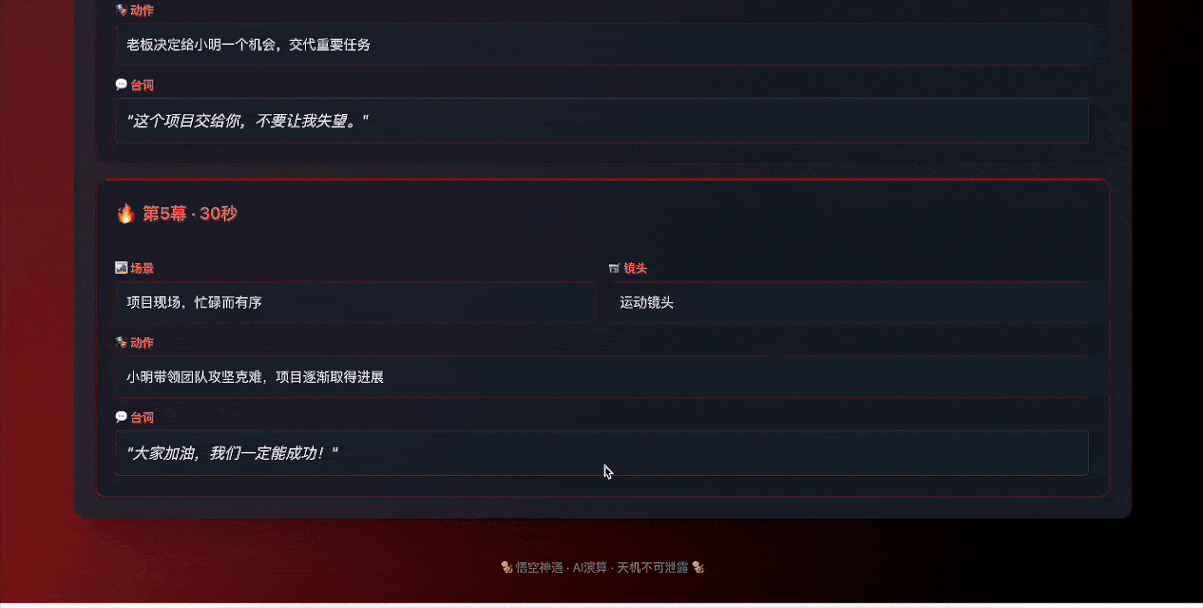
比如标题改成了”黑神话·短剧天机”,副标题改成了“悟空慧眼观世间,AI神笔写乾坤。一念生成千万剧,皆是因果皆是缘”,输入区域被定义为”天机演算法坛”,生成按钮标称了”演算天机剧本”。
Demo 7:荒岛求生游戏
提示词:设计一个“荒岛求生游戏”,用户输入想要的资源和技能,智能体生成一系列求生任务和情境,用户通过与系统的互动解决困境。
GLM-4.5的完成度非常高,设计了角色创建系统、生存系统、任务系统、随机事件系统和游戏进度系统。游戏会根据玩家当前技能和资源生成合适的任务,并在资源消耗、技能成长、风险回报上进行了平衡。
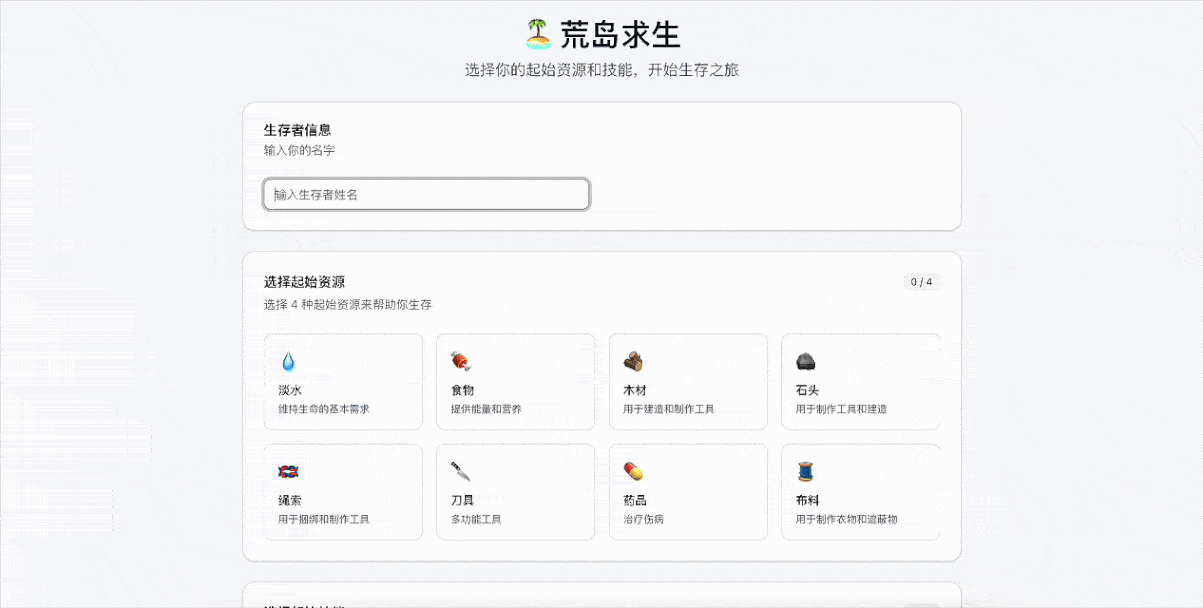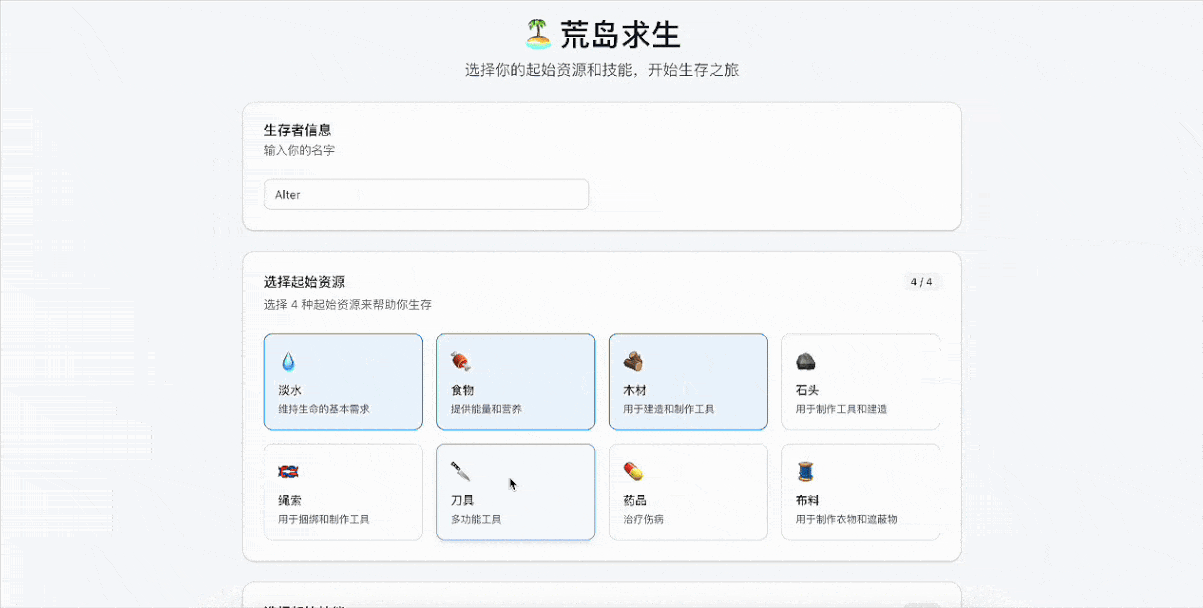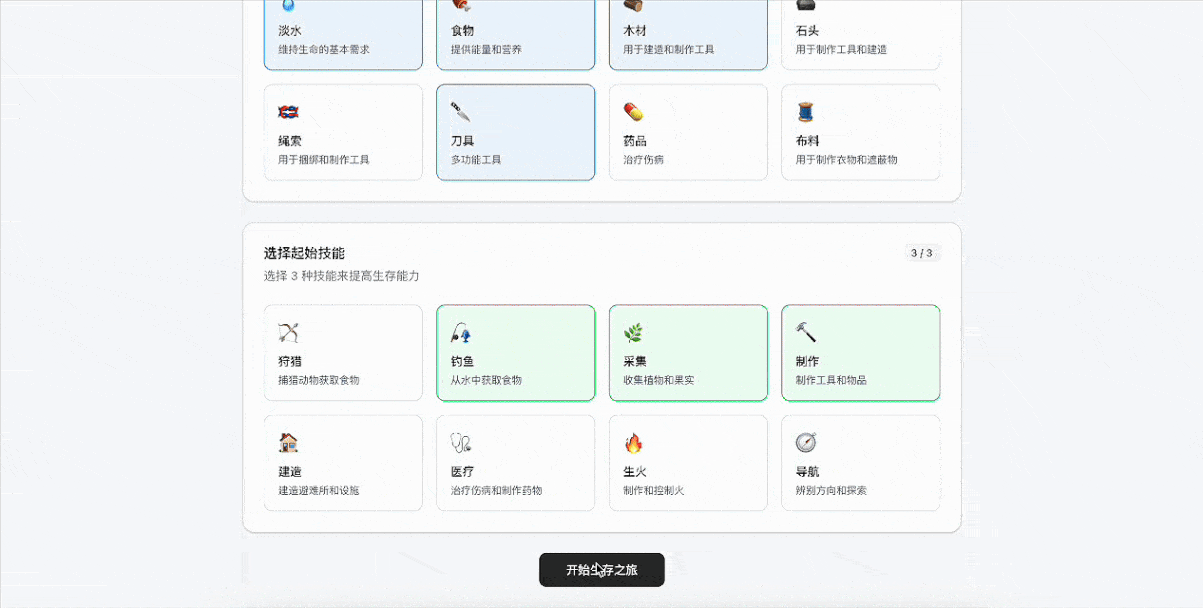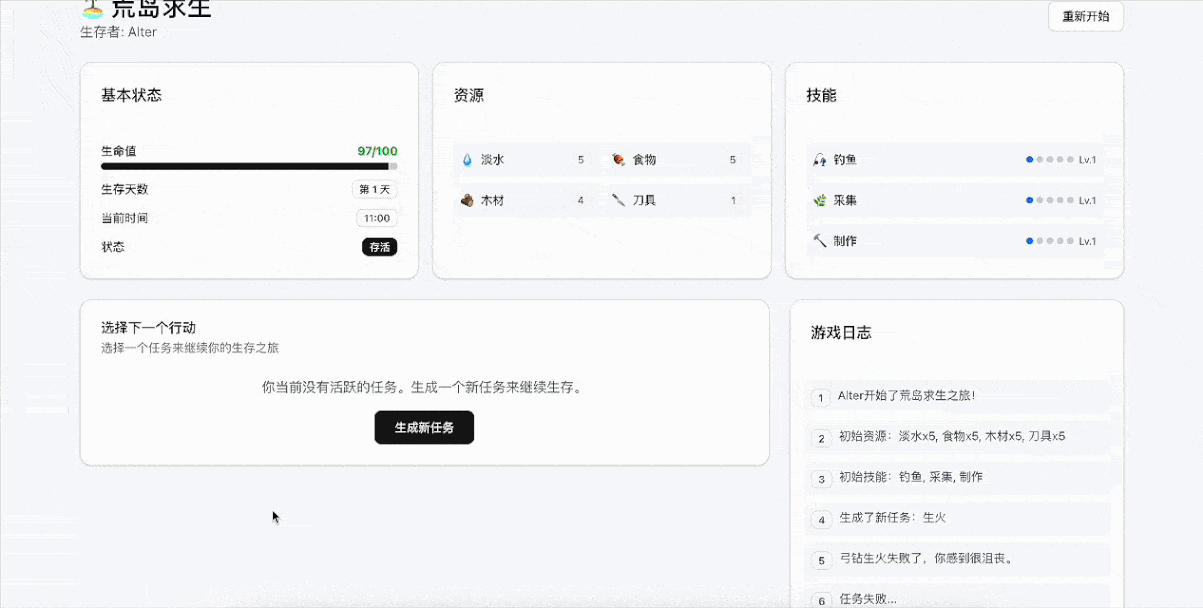
同时也在考验模型在情境生成、任务多样性、即时反馈以及决策等方面的能力。比如我们多次选择狩猎大型动物的任务,导致生命值不断下滑后,后续生成的任务主要是休息和安全探索,确保玩家可以“活下去”。
由于提示词比较简单,整个游戏的可玩性不是特别强,但让我们看到了一种新的可能:游戏公司在验证一个创意的可行性时,可以先简单做一个Agent,不断模拟游戏中的场景,丰富游戏的剧情。
Demo 8:诊疗陪练系统
提示词:做一个诊疗陪练应用,通过AI模拟患者,辅助医学生提升诊断技能,提供问诊评分,高效助力临床实践训练。另外再写一个管理员页面的功能,方便管理员查看医学生的成绩。
这个demo主要涉及两个部分:
1、诊疗陪练应用,通过AI模拟患者来辅助医学生提升诊断技能,提供问诊评分。
2、管理员页面功能,使管理员能够方便地查看医学生的成绩。
不管是AI对话系统的复杂性、评分算法的设计、数据模型的复杂性,还是实时交互的技术挑战、医学专业知识的准确性、系统集成和数据流的处理,几乎都在考验当前大模型的能力上限。
一个直接的例子,GLM-4.5需要理解医学生的提问和患者的回答,并且根据设定的医学背景、症状和情境模拟合理的互动。例如模拟患者可能表达各种症状,且这些症状需要结合医学知识进行适当的反馈。
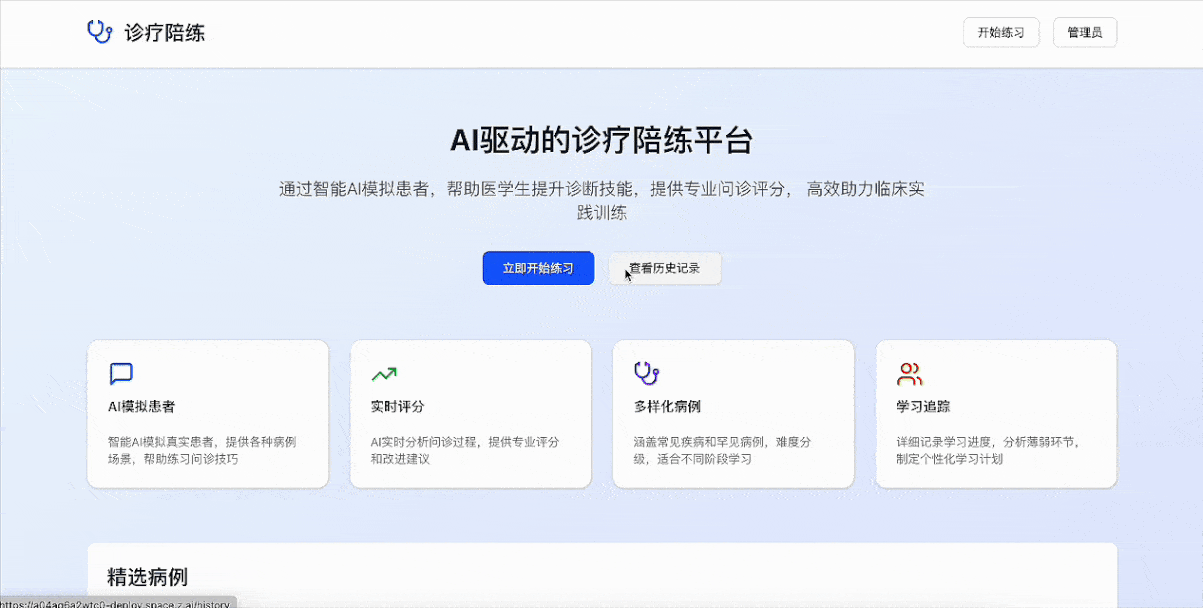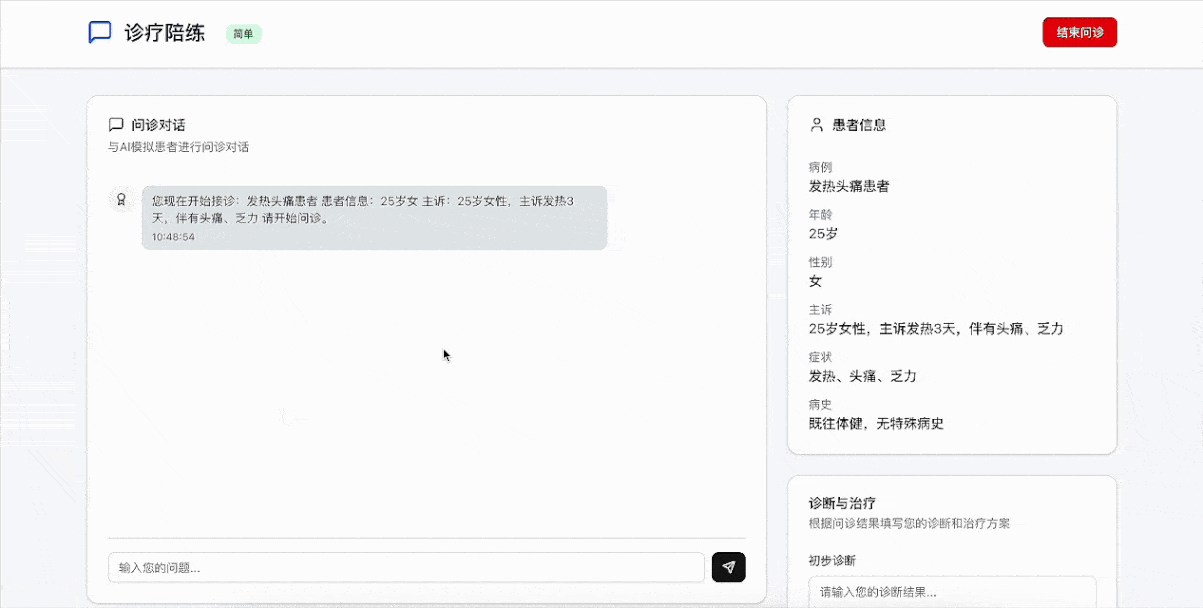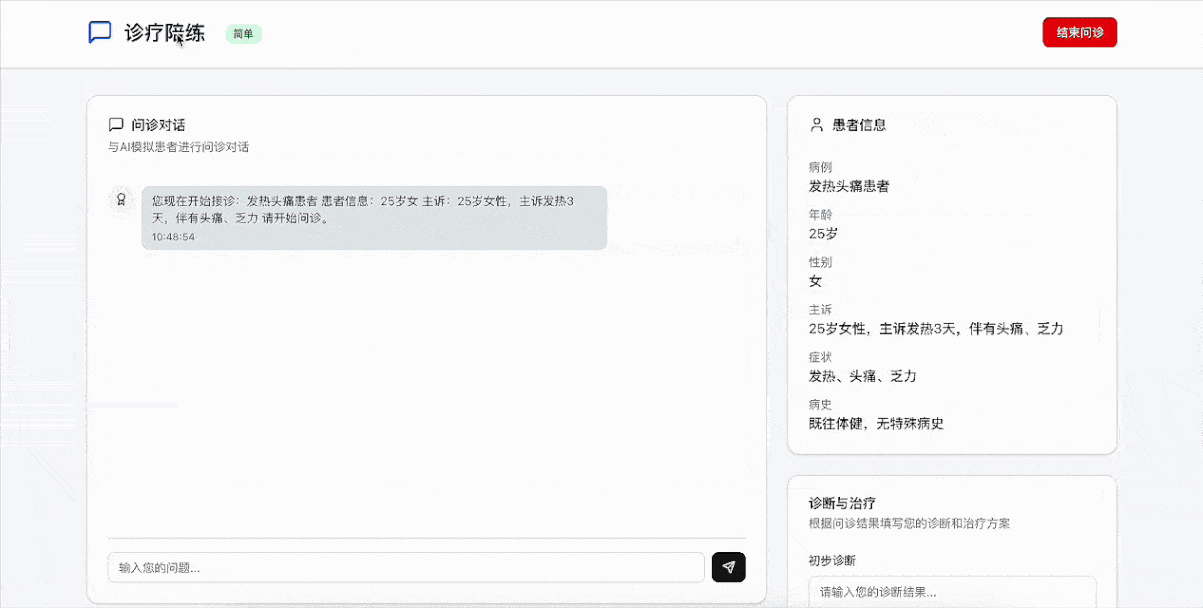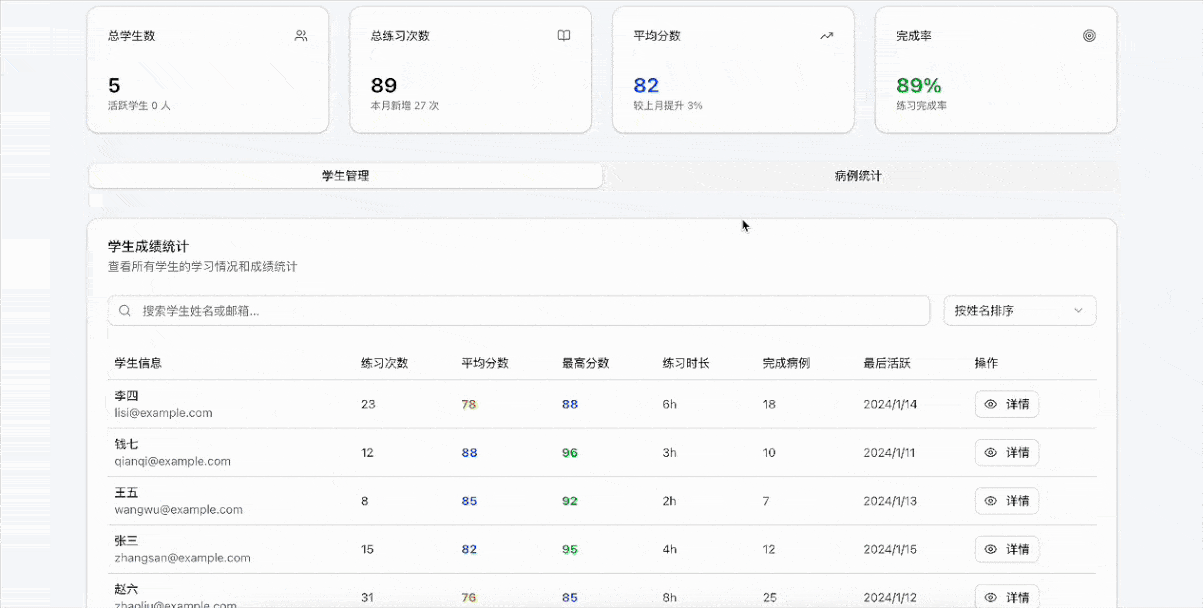
就交互体验和系统完整性而言,GLM-4.5的表现依旧值得称赞,只用了十几分钟的时间,但已经很接近一套完整的诊疗陪练系统,而且UI设计、题库设计、交互体验、数据管理等模块不逊于市场上的大多数成熟产品,验证了大模型生成复杂Agent系统的可能性。
一些思考
作为基座模型的GLM-4.5,同时扮演了产品经理、程序员和测试运维的角色,通过在一个模型中实现多种能力的融合,很大程度上简化了搭建智能体的工程难度,进一步拉低了智能体的应用门槛。
目前GLM-4.5只能部署8个实例,我们也只能展示8组Demo,但传递出的信号已经十分明显:
1、技术的门槛正在消失,创意将直接和生产力挂钩。
就像上述的Demo,即便是最简单的静态网页,至少需要一个前端和一个设计师协同,花费三四天的时间,现在只需要一句自然语言的指令,文案、配图、代码、上线部署等均可以交给GLM-4.5。
当技术的门槛被抹平了,创意的价值将被无限放大,即使是不懂技术的普通人,也能将创意转化为生产力。
2、智能体竞赛的逻辑即将重构,从“系统拼装”向“模型驱动” 转变。
过去智能体竞赛的焦点在于能否将不同的组件、工具和技术有效地集成到一起,更多依赖于工程实现,而非模型本身的创新。
智谱示范了另一种路线,即“模型即操作系统”的路线:通过大模型能力的全面提升,减少了工程集成的复杂性。一些简单的智能体能力,或将被基座大模型整合,但基座模型能力的增强,赋予了开发者更大的想象空间。
3、从比拼榜单刷分到真实场景表现,大模型厂商越来越务实。
GLM-4.5的基准评测成绩不可谓不亮眼,让我们印象最深刻却是在真实场景中的表现,代表着大模型的产业落地进程。
除了性能优化,GLM-4.5也在成本和效率上实现了突破,其中API调用价格已经低至输入0.8元/百万tokens,输出2元/百万tokens,高速版本实测生成速度超过100 tokens/秒,可以说兼顾成本效益与交互体验。
也让我们有理由相信,当GLM-4.5代表的新模型不断融合更多通用智能能力,AI“动手”的时代已经离我们越来越近,Agent正加速从实验室走向真实场景,成为日常生活中不可或缺的一部分。

